Geospatial Technologies – GIS and Remote Sensing and its applications using Machine Learning and Artificial Intelligence
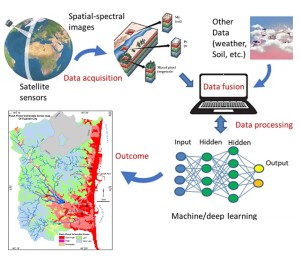
Machine learning (ML) is a branch of artificial intelligence where machines acquire knowledge and skills by analyzing machine-readable data and information. It utilizes data, acquires knowledge of patterns, and makes predictions about future outcomes. The popularity of this solution is increasing due to its ability to comprehend trends and offer both model-based and product-based solutions. The utilization of machine learning algorithms in the fields of geographic information systems (GIS) and remote sensing has experienced a significant surge in recent years. It has a broad range of applications, from developing energy-based models to assessing soil liquefaction to creating a relation between air quality and mortality. It utilizes data, acquires knowledge of patterns, and forecasts future outcomes. The popularity of this solution is increasing due to its ability to comprehend trends and offer a versatile solution, which can take the form of either a model or a product. The machine learning field encompasses four distinct approaches: supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning. Supervised learning involves the use of labeled training data, while unsupervised learning involves the use of unlabeled training data. Semi-supervised learning is a combination of supervised and unsupervised learning methods, in which the training data consists mostly of labeled information. Nevertheless, the model has the autonomy to independently discern the pattern in the data. Reinforcement learning involves the agent acquiring knowledge through repeated experimentation in order to make decisions and adapt to the dynamic environment. A machine learning project comprises multiple stages, and it is imperative to meticulously plan each stage.
The utilization of machine learning algorithms in G.I.S. and remote sensing has experienced a significant surge in recent years. It has a wide array of uses, ranging from constructing energy-based models to evaluating soil liquefaction to establishing a correlation between air quality and mortality. Additional instances encompass the assessment of satellite imagery sensor data for air quality at regional and urban scales, the utilization of a support vector machine technique to determine longitudinal dispersion coefficients in natural streams, the management of crises and disasters, the application of linear programming to schedule irrigation, the study of global climate change and weather forecasting, the evaluation of the accuracy of land cover classification, the investigation of air pollutants and their sources in relation to health effects, the identification of settlement features such as roads and ditches, the detection of crop diseases and estimation of crop yields, the analysis of vegetation indices, the response to natural disasters, and the management of disease outbreaks. Furthermore, researchers and users derive benefits from the accessibility of remote sensing datasets, which they can utilize to create, evaluate, and execute their machine learning models for their research purposes. The majority of remote sensing datasets are both global in coverage and unbiased in nature. This enhances the workflow in constructing precise ML models in this field. In addition, remote sensing-based research is not impeded by natural disasters or unforeseen incidents.
The predominant supervised models are non-parametric machine learning models that are applicable to a wide range of Geographic Information System (GIS) and remote sensing projects. In this discussion, we cover various classification models such as Naïve Bayes (NB), Support Vector Machine (SVM), Random Forest (RF), and Decision Trees (DT). Additionally, we explore regression models including Random Forest (RF), Support Vector Machine (SVM), Linear, Count, and Poisson. Binomial and multiclass classification models are more common in G.I.S. and remote sensing-based projects.
Machine learning models in G.I.S. and remote sensing that are supervised classification are:
Bayesian algorithms for naive classification
These supervised models are the most straightforward to construct, less intricate, and can be employed on extensive datasets. They exhibit high speed. Nevertheless, Naïve Bayes classification is not applicable to continuous numerical values. Due to its ability to disregard extraneous data, it may result in imprecise forecasts. The three types of Naïve Bayes are Gaussian, Multinomial, and Bernoulli. Gaussian assumes a normal distribution. The multinomial distribution is used to model discrete counts, while the Bernoulli distribution is used for binary outcomes. These classifiers demonstrate high efficiency in making predictions for multiple classes. These models can be best utilized in making best management practices models (B.M.P.s), habitat suitability models, and weather prediction.
Random Forest Classifier
This is a supervised classification model that can be utilized for both classification and regression tasks. It is an assemblage of decision trees that makes predictions by utilizing multiple models or sub-models. Hence, it is commonly referred to as the ensemble classifier. R.F. When creating models, the bagging principle is employed, which involves generating multiple models using different subsets of the training data. The final outcome is determined by the majority or average prediction of these sub-models. Several studies indicate that the quantity of trees typically does not have a substantial effect on the resulting random forest (R.F.) model. Classification accuracy improves as the number of trees in the classifier increases, as long as the number is sufficiently large. This means that adding more trees to the classifier leads to higher prediction accuracy. However, the precision tends to level off when using a significant number of trees. Several typical instances of projects that can be resolved using R.F. include: The algorithm encompasses various tasks, including land use and land cover classification, feature extraction such as identifying ditch segments, roads, settlements, or other objects of interest, object detection for identifying tree species, vehicles, and species identification for animals such as tigers, elephants, bird species, insects, and habitat classification.
Also undertaking projects involving modeling, such as assessing flood and drought risks, identifying core habitats, classifying soil types, studying diseases and weeds, and developing climate and weather forecasting models.
Support Vector Machine (SVM)
This is a machine learning model that can be utilized for both classification and regression tasks. The data is fitted by means of a clearly defined line referred to as a hyperplane. Due to its simplicity in construction and resistance to extreme data points, the model is extensively utilized in the fields of Geographic Information Systems (G.I.S.) and remote sensing. To construct a support vector machine learning model, the user must explicitly indicate the type of kernel to be used. Polynomial kernels and the radial basis function (RBF) kernel are widely used in remote sensing. SVM models can be used to classify satellite-based imagery and detect features such as roads, wetlands, and grasslands.
These models are widely recognized as the most popular research models in the fields of Geographic Information Systems (G.I.S.) and remote sensing. Linear regression is a statistical method used to analyze the relationship between multiple factors or covariates. It is particularly useful when considering spatial analysis and the impact of distance features, such as the influence of proximity to water on habitat selection.
Three types of linear regression are frequently employed in GIS and remote sensing projects. They are Continuous (Gaussian), Logistic and Poisson distribution. The distribution must adhere to the normality assumption for Gaussian distribution linear regression. The term "continuous" is used because the dependent variable has the ability to encompass a broad spectrum of values, such as temperature, rainfall, and tree diameter. If the dependent variable is not normally distributed, we can change it to binary values using reclassify function. Binary, also referred to as logistic regression models, constructs models that have only two possible outcomes: pass/fail or presence/absence. If the dependent variables represent the frequency or occurrence of an event, we employ count/Poisson regression models.
In recent years, ML models are increasingly being used in GIS and remote sensing based projects. ML models aid in addressing GIS and remote sensing issues by discerning the fundamental patterns, such as categorizing satellite imagery, detecting features such as roads, wetlands, and grasslands, and performing image segmentation. We will explore several well-known machine learning models and their practical implementation in projects involving geographic information systems (GIS) and remote sensing.
Researchers can utilize this information as a point of reference when initiating a machine learning-based project. There are additional machine learning models that can be easily learned after mastering the aforementioned models.